
Ahead of the NBA playoffs, I put together this n8n + MongoDB demo in about 30 minutes for last night's meetup. I wanted something more useful than opinions.
I did not want to show up saying workflow automation seems important, or that agents probably need memory, or that databases might matter more in the future. I wanted a small stack I could run locally, explain in a few minutes, and hand to someone without a lot of hand-waving.
One disclosure up front: I work at MongoDB now, so take that into account. That said, this is the architecture lesson that genuinely clicked for me while building the demo.
So this post is not really a grand theory. It is a small MongoDB + n8n cookbook: three recipes, one local Docker stack, and one idea underneath all of it.
Once workflows have a memory layer, they stop looking like automations and start looking like software.
Stack
Here is what went into the stack:
- self-hosted
n8nin Docker MongoDB 7in DockerFirecrawlfor web scrapingOpenRouteras the LLM gatewayGemini Flashas the modeln8nLangChain nodes for the AI layer
That stack is not interesting because it is exotic. It is interesting because it is enough. You get orchestration, persistence, scraping, enrichment, and one place to store the state that comes out the other side. That is enough to make the shape of the system obvious without building a full application around it.
Recipe 1: Scrape, Summarize, Store
This was the simplest recipe in the set, and also the one that makes the point fastest. Take a webpage, scrape it with Firecrawl, pass the content through Gemini for summarization, and insert the result into MongoDB.
That sounds almost too basic to deserve a demo. It does anyway, because it proves two things right away.
First, n8n is very good at taking a sequence that would normally require a little backend glue code and turning it into a visible workflow in a few nodes. Trigger, fetch, enrich, store. The outer loop is fast to build.
Second, MongoDB is a natural place to put the result because the output is not really stable yet. A scraped page today might become:
urltitleraw_contentsummarytagssentimententitiessource_type
And tomorrow you may want:
- a confidence score
- a topic classification
- an embedding
- a reviewer note
- a processing status
That is not unstructured data. It is evolving structured data.
That distinction matters. People sometimes say MongoDB is for unstructured data, but that is a little too sloppy. The stronger claim is that MongoDB is good when the data has structure, but the structure keeps changing as the workflow matures. That is exactly what an AI enrichment pipeline tends to produce.
The tiny version of the pattern is enough to show it: workflow tools get much more useful when the output can evolve without turning every small schema change into a negotiation.
Recipe 2: Any URL In, Enriched Document Out
The second recipe took the first one and made it feel like an actual interface. Instead of starting from a fixed page, I added a webhook so I could POST any URL into the workflow and get back an AI-enriched MongoDB document in real time.
That changed the feel of the stack immediately. The first workflow was a good enrichment demo. The second workflow felt more like application behavior.
This is one of the more useful things about n8n. It is easy to underestimate it if you only think of it as automation software. Once you add a webhook, a few transformations, an AI step, and a database write, you start getting something that behaves like a lightweight service.
And again, the database choice matters for a practical reason.
When every incoming page has a slightly different shape, slightly different metadata, and slightly different downstream value, you usually do not want the storage layer to become the rigid part of the system. You want to capture the result first, then decide later what deserves stronger structure, indexing, retention, or retrieval logic.
That is the pattern I keep coming back to with agent and workflow systems:
- raw event comes in
- workflow enriches it
- enriched state lands somewhere durable
- later workflows build on top of that state
If you do not store the result, the workflow is basically a trick. If you do store the result, the workflow starts to become memory.
Recipe 3: A Chatbot with Live Data and Memory
The third recipe is the one that made the whole stack click, because it was not really one workflow. It was three connected workflows acting on the same state layer.
The first of those kept the underlying sports data fresh. On a schedule, n8n scraped the latest standings, merged the results, prepared a clean log entry, and wrote the refresh back into MongoDB. There is a refresh loop underneath the chatbot, and MongoDB is where the updated domain state lands.
The second workflow exposed that domain state as agent-usable context. When called by the AI agent, n8n fetched games, standings, players, injuries, and storylines from MongoDB, tagged each result set, merged them, and formatted the final payload for the model. That part is worth showing because "tool use" can sound mystical if you only describe it in words. In practice, it is often just workflow logic pulling multiple pieces of state together and handing the model a clean, structured context object.
On top of those two workflows, I built a simple sports chatbot with two MongoDB collections behind it:
- a
gamescollection holding upcoming game data - a
chat_historiescollection storing every conversation turn
The model could answer questions about the games, pull live domain context from the schedule collection, and keep the conversation going by writing the history back into MongoDB.
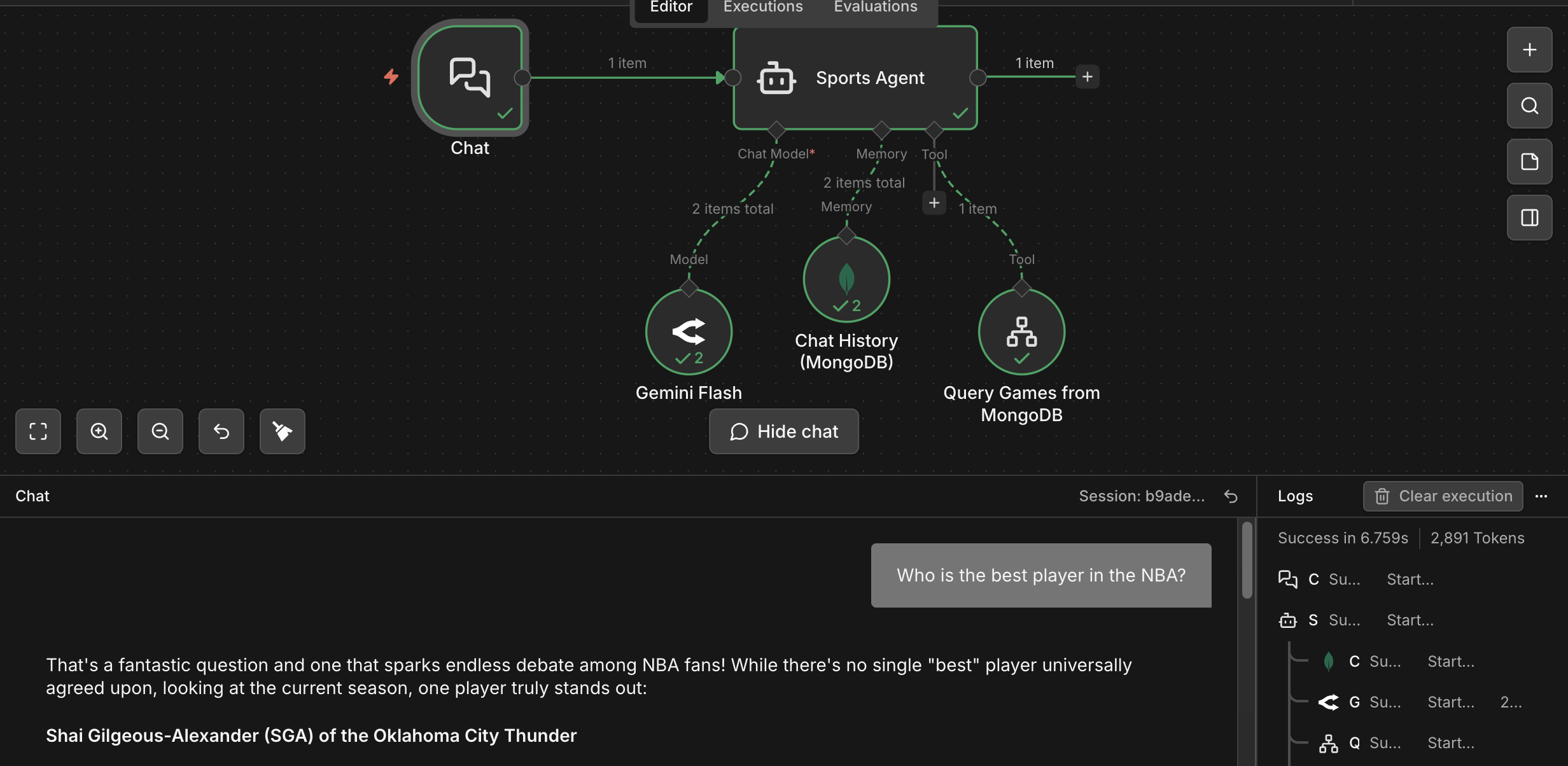
This is the workflow where the architecture became easy to see:
- chat trigger on the left
- the agent in the middle
- model connection underneath
- MongoDB chat history as memory
- MongoDB query tool for the games data
That is the picture I wish more people had in their head when they talk about agents: not a disembodied model floating in space, but a workflow engine orchestrating the loop, a model doing reasoning, and a database holding the state the system needs in order to keep going.
The sports part is not actually the important part. What matters is that the database is doing several jobs at once:
- refresh destination for newly scraped domain data
- source of truth for the agent's tool context
- operational storage for the domain data
- episodic memory for the conversation itself
That is a much better pattern than treating memory as some vague future add-on.
It also made one line feel very true:
n8n orchestrates. MongoDB remembers.
Once you see the stack that way, a lot of the "AI workflow" conversation gets less fuzzy.
Notes
A few things clicked for me while building this.
JSON is inescapable
One of my big takeaways from the meetup was that JSON really is the boring substrate behind a lot of these systems. Tool calls are JSON-shaped. Webhook payloads are JSON-shaped. Workflow state is JSON-shaped. Agent memory often becomes JSON-shaped.
That does not mean JSON alone solves memory. It does not. You still need retrieval, timestamps, summaries, IDs, and a way to separate raw traces from useful memory. But it does mean the state flowing through agent systems tends to want structure without rigidity.
That is why the connection to MongoDB feels real. Agents do not just need unstructured blobs. They need evolving document-shaped state.
The useful split is orchestration versus memory
This stack made me think about the architecture in a cleaner way.
n8n is very good at the outer loop:
- triggers
- webhooks
- routing
- API calls
- multi-step workflows
MongoDB is good at the state layer:
- domain data
- scraped and enriched documents
- conversation histories
- records whose shape gets richer over time
That is a very useful split.
Small demos are better when they prove a reusable pattern
The best part of this stack is not that I connected n8n to MongoDB. Of course I connected n8n to MongoDB. That is the easy part.
The more useful part is that the three recipes point at the same general pattern:
- enrich data and store it
- turn a webhook into a stateful endpoint
- give a chatbot both live domain data and memory
Those are not isolated parlor tricks. They are building blocks.
What I'd Build Next
If I kept going, these are the next things I would add:
- a summarization layer that compacts old chat history into episodic memory
- approval steps before certain writes
- a second tool so the agent has to choose between multiple data sources
- a retrieval layer over stored summaries and scraped pages
- a domain switch so the exact same stack can move from sports to something like support, media, or GTM research
That is the part I like most about this architecture. It is not precious. You can swap out the domain and keep the shape.
The Real Lesson
I did not walk into the meetup trying to prove that n8n is the future or that MongoDB is the answer to everything. I just wanted something real.
What I ended up with was a much cleaner intuition about where these systems get interesting. A scraper that stores something is better than a scraper that prints something. A webhook that enriches and persists is better than a webhook that just returns text. A chatbot that can read domain data and remember prior turns is more interesting than a chatbot that improvises from scratch every time.
That is the lesson I would keep. Not a huge platform claim. Just this:
Once workflow tools have a memory layer, they stop looking like automations and start looking like software.